
braintools.surrogate.PiecewiseExp#
- class braintools.surrogate.PiecewiseExp(alpha=1.0)#
Judge spiking state with a piecewise exponential function.
This class implements a surrogate gradient method for spiking neural networks using a piecewise exponential function. It provides a differentiable approximation of the step function used in the forward pass of spiking neurons.
- Parameters:
alpha (
float) – A parameter controlling the steepness of the surrogate gradient. Higher values result in a steeper gradient. Default is 1.0.
See also
piecewise_expFunction version of this class.
Examples
>>> import braintools >>> import brainstate >>> import jax.numpy as jnp >>> >>> # Create a piecewise exponential surrogate >>> pe_fn = braintools.surrogate.PiecewiseExp(alpha=1.0) >>> >>> # Apply to membrane potentials >>> x = jnp.array([-1.0, 0.0, 1.0]) >>> spikes = pe_fn(x) >>> print(spikes) # [0., 1., 1.] >>> >>> # Use in a leaky integrate-and-fire neuron >>> import brainstate.nn as nn >>> >>> class LIFNeuron(nn.Module): ... def __init__(self, tau=20.0): ... super().__init__() ... self.tau = tau ... self.spike_fn = braintools.surrogate.PiecewiseExp(alpha=2.0) ... self.v = 0.0 ... ... def forward(self, input_current, dt=1.0): ... self.v = self.v + dt/self.tau * (-self.v + input_current) ... spike = self.spike_fn(self.v - 1.0) # Threshold at 1.0 ... self.v = self.v * (1 - spike) # Reset ... return spike
>>> import jax >>> import braintools >>> import brainstate as brainstate >>> import matplotlib.pyplot as plt >>> xs = jax.numpy.linspace(-3, 3, 1000) >>> for alpha in [0.5, 1., 2., 4.]: >>> pe_fn = braintools.surrogate.PiecewiseExp(alpha=alpha) >>> grads = brainstate.augment.vector_grad(pe_fn)(xs) >>> plt.plot(xs, grads, label=r'$\alpha$=' + str(alpha)) >>> plt.legend() >>> plt.show()
(
Source code,png,hires.png,pdf)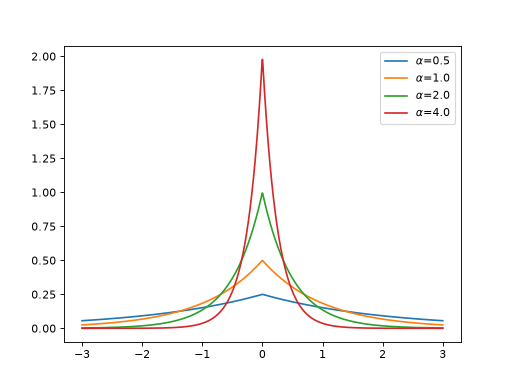
Notes
The forward pass uses a Heaviside step function (1 for x >= 0, 0 for x < 0), while the backward pass uses a piecewise exponential surrogate gradient.
The piecewise exponential function provides smooth gradients that decay exponentially with distance from the threshold, which can help with gradient flow in deep networks.
The surrogate gradient is defined as:
\[\begin{split}g'(x) = \\frac{\\alpha}{2} e^{-\\alpha |x|}\end{split}\]References
Methods
__init__([alpha])surrogate_fun(x)Compute the surrogate function.
surrogate_grad(x)Compute the surrogate gradient.
{kind=link}
{kind=link}